
Sample opinion surveys are a well-established way to measure public opinion on contemporary affairs. However, the exponential growth of social media in the 21st century opens new possibilities in social research. This post considers the Northern Ireland Young Life & Times Survey as a case study of contemporary surveying, in order to consider the potential of social media based research to complement and strengthen the findings of existing ‘conventional’ research methods.
Young Life & Times Survey
‘All too often the opinions of young people are ignored when decisions are made about many of the issues involving them.’ Thus, the Young Life & Times (YL&T) Survey has, since 2003, gauged the views of 16-year-olds across Northern Ireland on topics including politics, community relations and education.
The Survey is delivered by Queen’s University Belfast and supported by a range of funders including the Department of Justice and The Executive Office. Along with its counterparts, the NI Life & Times Survey (engaging adults) and the Kids’ Life & Time Survey (engaging 10/11 year olds), it informs policy development for these and other Departments.
Nonresponse
Response rates to the Survey are, however, quite low. As the chart below demonstrates, the Young Life & Times response rate has fallen from 74% in 1998 to 23% in each of the last 3 years. This contrasts with its counterpart the NI Life & Times Survey, which has also fallen substantially from a peak response rate of 70% in 1999, but has remained consistently in the mid-50s since 2012.
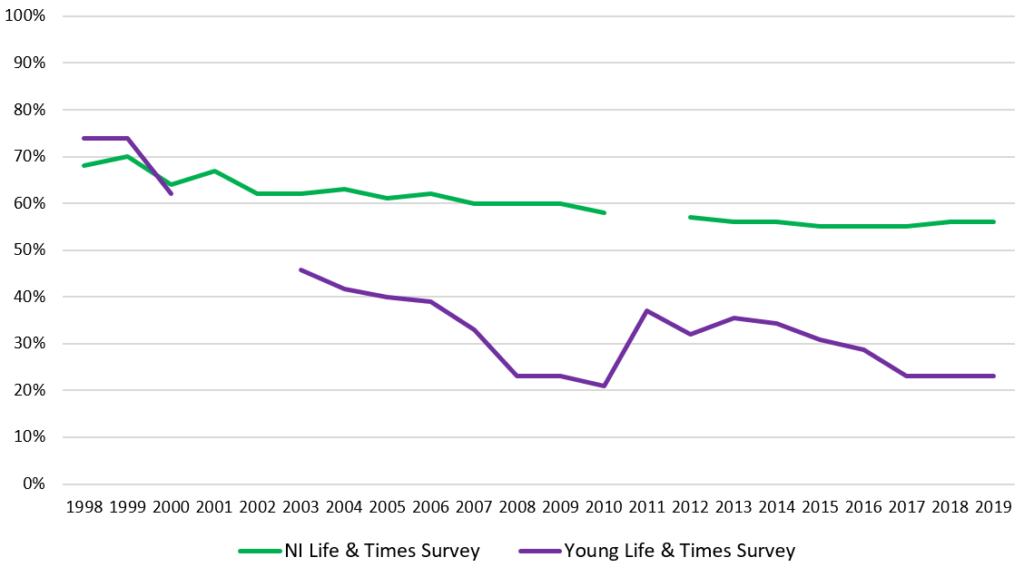
Low response rates are not an issue particular to the YL&T survey; indeed, they are a growing trend across developed nations in recent decades. It is also true that low response rates do not automatically undermine the value of survey results: however, they do lead to the risk of nonresponse bias, whereby survey respondents differ from the survey’s target population in some meaningful way. This can damage a survey’s core validity, while efforts to address the issue can also lead to increased cost and complexity in delivering a survey and processing the data gathered.
A role for social media based research?
Two thirds of all people in Northern Ireland, and 95% of 16-24 year olds across the UK, have at least one social media account. There is clear and significant potential in research methods stepping beyond the bounds of conventional surveys and utilising organic social media data for (for instance) sentiment analysis – whereby social media users’ posts are analysed to identify and extract meaningful information on areas of interest, such as young people’s opinions on the GCSE system or Brexit. Research of this kind has several potential strengths, but also numerous current limitations.
Once data collection parameters are in place, social media-based research can be much quicker to collect and analyse, and potentially cheaper in the long term, than a conventional survey. Social media data also hold the potential for very large samples, with the ability to improve overall validity and permit closer analysis of relevant demographics within an overall target group. Finally, this form of research can capture the perspectives of individuals who do not respond to surveys, as well as capturing respondents’ views as they behave in a more organic or ‘natural’ way within online social networks.
Amid all of this potential, however, there are significant current challenges and limitations to using social media data for robust research.
First, despite continuing growth of platforms enabling social media data analysis, significant computing capacity and skill is required to design specific data collection parameters and procedures.
Secondly, social media data itself must be treated with caution on several fronts. Data from a social media user sample is rarely inherently representative of a larger target population, which has implications for representativeness and validity. Researchers have also highlighted how users’ own social media content is proactively and performatively generated, leading to a risk that data is biased in favour of the most enthusiastic, motivated or extroverted individuals on a given platform. The ways in which online platforms steer and influence user behaviour – such as algorithms underlying Facebook and Twitter news feeds, suggested connections on those sites, and Google search auto-completes – may also affect the validity of the data collected there.
Finally and significantly in the context of GDPR obligations, direct and individual informed consent, when collating social media data at scale, is almost impossible. Researchers to date have generally taken an approach of minimising harm and risk to research subjects through anonymization, secure data storage and reporting only aggregate level results; this is, however, an element of the research process that requires additional care in the context of social media data.
Future development
Conventional sample surveys are a well-established way to measure public opinion. However, survey research also has several potential weaknesses, including falling response rates, cost and the complexity of data processing. In this context, social media-based research has vast potential; however, in its current state it also has many limitations, challenges and immaturities as the area of research continues to develop.
Given this, several researchers have recommended that any social media data, or statistics drawn from this, be initially benchmarked against existing ‘traditionally produced’ statistics on the same topic as a comparison and sense-check.
In the medium term, social media-based data could usefully inform specific ‘indicators’ which complement larger and less regular survey statistics: for example, the annual Young Life & Times Survey could be accompanied by quarterly bulletins reflecting the perspectives of young people on social media on one or more chosen topics covered in the Survey. Piloting such a process could take advantage of the attributes of social media research, particularly its speed and size, as well as informing potential future development of research in this area.